💻 API Keys & SQL Database
Soowan Choi
API Keys & SQL Database
Collect Data API → Clean Data → Store on Database → Build Model → Visual Output

API Keys: https://developers.google.com/youtube/v3/getting-started
Collect Data API → Clean Data
# import libraries
import requests # to make API calls
import pandas as pd # to save dataframe
import time
import re # for regex
1) Setup URL (with API Key) –> Call API
# keys
api_key = '___________________________' # youtube API key
channel_id = '________________________' # youtube channel ID
# url = "https://www.googleapis.com/youtube/v3/videos?id=7lCDEYXw3mM&key=" + api_key + "&fields=items(id,snippet(channelId,title,categoryId),statistics)&part=snippet,statistics"
# make API call
pageToken = ""
url = 'https://www.googleapis.com/youtube/v3/search?key=' + api_key +'&channelId=' + channel_id + '&part=snippet,id&order=date&maxResults=10000' + pageToken
# url = "https://www.googleapis.com/youtube/v3/videos?id=7lCDEYXw3mM&key=" + api_key + "&fields=items(id,snippet(channelId,title,categoryId),statistics)&part=snippet,statistics"
videos = requests.get(url).json() # .get() function to make the API call and grab data from that call and return as .json() object
videos
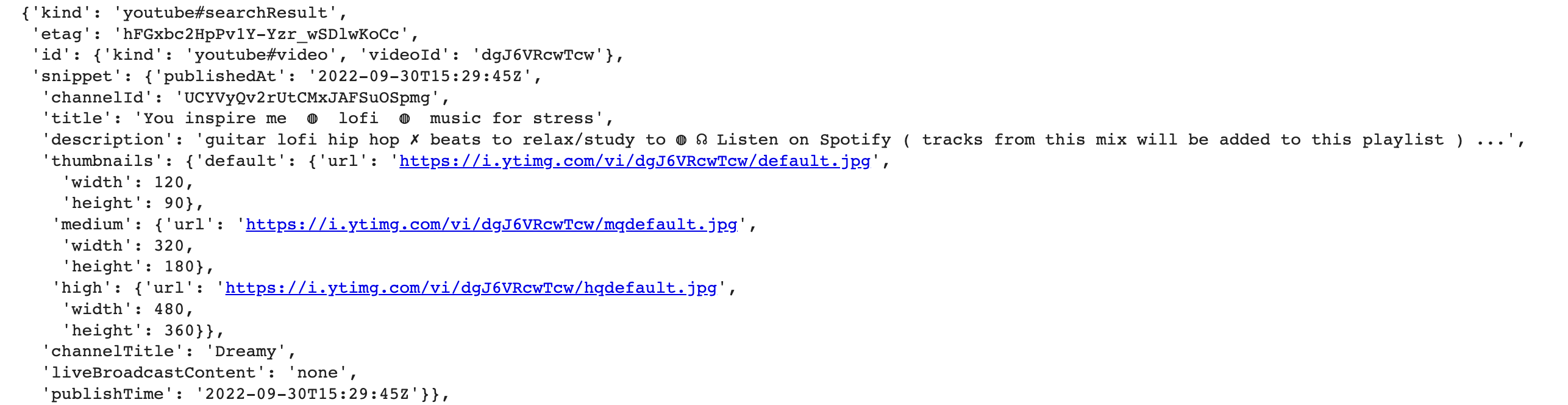
2) Extract Content from API Call
For Single Video
Store Items of Interest
# try to select the first video and ID
videos['items'][0]['id']['videoId']
# store interested items into variables
video_id = videos['items'][0]['id']['videoId']
video_title = videos['items'][0]['snippet']['title']
date_upload = videos['items'][0]['snippet']['publishTime'].split('T')[0]
Clean Title (using .replace and Regex)
- For each character in string
- If the character is not a letter and not a space
- Replace the character
- Remove all extra space
print("Different characters & Large Spaces:\n", video_title,"\n")
print("Remove Different Characters:")
for char in video_title:
if str(char.isalpha()) == 'False' and str(char.isspace()) == 'False':
video_title = video_title.replace(char, "")
print(video_title, "\n")
# replace all blanks/newlines/tabs (\s in regex) if there are at least 1 of them by one space
print("Remove Large Spaces:\n", re.sub("\s{1,}"," ",video_title))

for char in video_title:
if str(char.isalpha()) == 'False' and str(char.isspace()) == 'False':
video_title = video_title.replace(char, "")
video_title = re.sub("\s{1,}"," ",video_title)
video_title
For All Videos
# run through all the videos
for vid in videos['items']:
# we only want youtube videos
if vid['id']['kind'] == "youtube#video":
# store items of interest
video_id = vid['id']['videoId']
date_upload = vid['snippet']['publishTime'].split('T')[0]
video_title = vid['snippet']['title']
# clean title
for char in video_title:
if str(char.isalpha()) == 'False' and str(char.isspace()) == 'False':
video_title = video_title.replace(char, "")
video_title = re.sub("\s{1,}"," ",video_title)
print(video_id, date_upload, video_title)

3) Second API Call (using 1&2)
1) Setup URL (with API Key) –> Call API
# setup second URL
url_stats = "https://www.googleapis.com/youtube/v3/videos?id=" + video_id + "&part=statistics&key=" + api_key
# call API
video_stats = requests.get(url_stats).json()
video_stats

2) Extract Content from API Call
video_stats['items'][0]['statistics']

views = video_stats['items'][0]['statistics']['viewCount']
likes = video_stats['items'][0]['statistics']['likeCount']
comments = video_stats['items'][0]['statistics']['commentCount']
# run through all the videos
for vid in videos['items']:
# we only want youtube videos
if vid['id']['kind'] == "youtube#video":
# store items of interest
video_id = vid['id']['videoId']
date_upload = vid['snippet']['publishTime'].split('T')[0]
video_title = vid['snippet']['title']
# clean title
for char in video_title:
if str(char.isalpha()) == 'False' and str(char.isspace()) == 'False':
video_title = video_title.replace(char, "")
video_title = re.sub("\s{1,}"," ",video_title)
# Second API CALL
url_stats = "https://www.googleapis.com/youtube/v3/videos?id=" + video_id + "&part=statistics&key=" + api_key
video_stats = requests.get(url_stats).json()
views = video_stats['items'][0]['statistics']['viewCount']
likes = video_stats['items'][0]['statistics']['likeCount']
comments = video_stats['items'][0]['statistics']['commentCount']
print(video_id, date_upload, video_title)
print(f"Views:{views}, Likes: {likes}, Comments: {comments}")
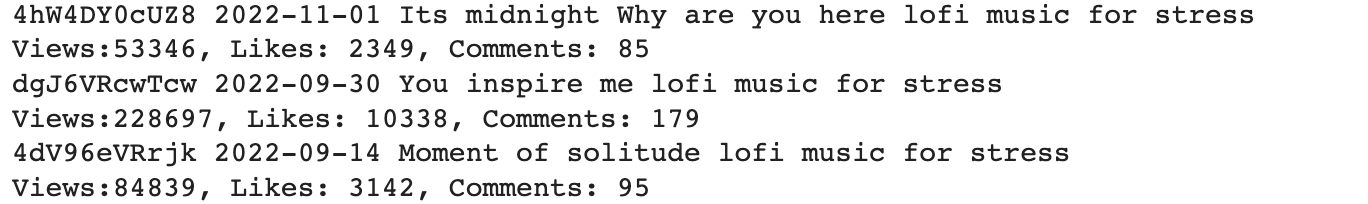
4) Save to DataFrame
# empty dataframe with column names
youtube_df = pd.DataFrame(columns = ['video_id','date_upload','video_title','views','likes','comments'])
youtube_df
# run through all the videos and save statistics to dataframe
for vid in videos['items']:
# we only want youtube videos
if vid['id']['kind'] == "youtube#video":
# store items of interest
video_id = vid['id']['videoId']
date_upload = vid['snippet']['publishTime'].split('T')[0]
video_title = vid['snippet']['title']
# clean title
for char in video_title:
if str(char.isalpha()) == 'False' and str(char.isspace()) == 'False':
video_title = video_title.replace(char, "")
video_title = re.sub("\s{1,}"," ",video_title)
# SEconD API CALL
url_stats = "https://www.googleapis.com/youtube/v3/videos?id=" + video_id + "&part=statistics&key=" + api_key
video_stats = requests.get(url_stats).json()
views = video_stats['items'][0]['statistics']['viewCount']
likes = video_stats['items'][0]['statistics']['likeCount']
comments = video_stats['items'][0]['statistics']['commentCount']
# save to dataframe
youtube_df = youtube_df.append(
{"video_id": video_id, "date_upload": date_upload, "video_title": video_title,
"views": views, "likes": likes, "comments": comments},
ignore_index = True
)
youtube_df

5) Break Code into Functions
# empty dataframe with column names
youtube_df = pd.DataFrame(columns = ['video_id','date_upload','video_title','views','likes','comments'])
youtube_df
def get_stats(video_id):
# 3) Second API Call (using 1&2)
url_stats = "https://www.googleapis.com/youtube/v3/videos?id=" + video_id + "&part=statistics&key=" + api_key
video_stats = requests.get(url_stats).json()
views = video_stats['items'][0]['statistics']['viewCount']
likes = video_stats['items'][0]['statistics']['likeCount']
comments = video_stats['items'][0]['statistics']['commentCount']
return views, likes, comments
def get_video(youtube_df):
# 1) Setup URL (with API Key) --> Call API
pageToken = ""
url = 'https://www.googleapis.com/youtube/v3/search?key=' + api_key +'&channelId=' + channel_id + '&part=snippet,id&order=date&maxResults=10000' + pageToken
videos = requests.get(url).json() # .get() function to make the API call and grab data from that call and return as .json() object
# make sure all data is collected in the API call 'requests' before starting analysis
time.sleep(1)
# 2) Extract content from API Call
for vid in videos['items']:
# we only want youtube videos
if vid['id']['kind'] == "youtube#video":
# store items of interest
video_id = vid['id']['videoId']
date_upload = vid['snippet']['publishTime'].split('T')[0]
video_title = vid['snippet']['title']
# clean title
for char in video_title:
if str(char.isalpha()) == 'False' and str(char.isspace()) == 'False':
video_title = video_title.replace(char, "")
video_title = re.sub("\s{1,}"," ",video_title)
# 3) Second API Call (using 1&2)
views, likes, comments = get_stats(video_id)
# 4) Save to DataFrame
youtube_df = youtube_df.append(
{"video_id": video_id, "date_upload": date_upload, "video_title": video_title,
"views": views, "likes": likes, "comments": comments},
ignore_index = True
)
return youtube_df
Test Function
youtube_df = pd.DataFrame(columns = ['video_id','date_upload','video_title','views','likes','comments'])
youtube_df = get_video(youtube_df)
# which video has the most views?
youtube_df[youtube_df['views'].astype(int).values == youtube_df['views'].astype(int).max()]

Store on Database
- save local memory
- store different versions of data
“Creating an RDS PostgreSQL Database on the AWS Free Tier”
https://www.youtube.com/watch?v=I_fTQTsz2nQ
REFERENCE: https://www.youtube.com/watch?v=77IVf0zgmwI
# # save dataframe as csv file --> stored on left pane 'files'
# youtube_df.to_csv('youtube_df.csv')
!pip install psycopg2
import psycopg2 as ps # to connect to PostgreSQL
import pandas as pd
# dataframe to upload to database
youtube_df.head()
# connect to PostgreSQL database
def connect_database(hostname, dbname, username, password, port):
try:
con = ps.connect(host=hostname, database=dbname, user=username , password=password, port=port)
except ps.OperationalError as e:
raise e
else:
print("successfully connected")
return con
def create_table(cur):
create_table_command = ("""CREATE TABLE IF NOT EXISTS videos (
video_id VARCHAR(255) PRIMARY KEY,
date_upload DATE NOT NULL DEFAULT CURRENT_DATE,
video_title TEXT NOT NULL,
views INTEGER NOT NULL,
likes INTEGER NOT NULL,
comments INTEGER NOT NULL
)""")
cur.execute(create_table_command)
def insert_to_table(cur, video_id, date_upload, video_title, views, likes, comments):
videos_insert = ("""INSERT INTO videos (video_id, date_upload, video_title,
views, likes, comments)
VALUES(%s,%s,%s,%s,%s,%s);""")
row_to_insert = (video_id, date_upload, video_title, views, likes, comments)
cur.execute(videos_insert, row_to_insert)
def row_update(cur, video_id, video_title, views, likes, comments):
query = ("""UPDATE videos
SET video_title = %s,
views = %s,
likes = %s,
comments = %s
WHERE video_id = %s;""")
vars_update = (video_title, views, likes, comments, video_id)
cur.execute(query, vars_update)
def check_video_exists(cur, video_id):
query = ("""SELECT video_id FROM VIDEOS WHERE video_id = %s""")
cur.execute(query, (video_id,))
return cur.fetchone() is not None
def truncate_table(cur):
truncate_table = ("""TRUNCATE TABLE videos""")
cur.execute(truncate_table)
def dataframe_to_database(cur,df):
for i, row in df.iterrows():
insert_to_table(cur, row['video_id'], row['date_upload'], row['video_title'], row['views']
, row['likes'], row['comments'])
def update_db(cur,df):
tmp_df = pd.DataFrame(columns=['video_id', 'date_upload', 'video_title', 'views',
'likes', 'comments'])
for i, row in df.iterrows():
# video already exists
if check_video_exists(cur, row['video_id']):
# update dataframe
row_update(cur,row['video_id'],row['video_title'],row['views'],row['likes'], row['comments'])
# video doesn't exist
else:
# add video to a temporary dataframe and then append using dataframe_to_database
tmp_df = tmp_df.append(row)
return tmp_df
# we are using amazon rds PostgreSQL database
hostname = "_____.rds.amazonaws.com"
dbname = "______"
username = "_______"
password = "_______"
port = "5432"
connection = None
# connect to database
connection = connect_database(hostname, dbname, username, password, port)
# .cursor() command allows you to run SQL commands and get results from the database
cur = connection.cursor()
# create the table
create_table(cur)
# update data for existing videos
new_vid_df = update_db(cur,youtube_df)
# .commit() command to execute SQL command to database
connection.commit()
# insert new videos into database
dataframe_to_database(cur, new_vid_df)
connection.commit()
# view database table
cur.execute("SELECT * FROM VIDEOS")
print(cur.fetchall())
-수완-